
After six years of focused development in the open, we’re proud to announce the release of Kedro 1.0: a major milestone that marks the maturity of Kedro as a data science framework.
In June 2019, we released Kedro 0.14.0 as an open-source framework to enable data scientists, data engineers, and machine-learning engineers worldwide to create maintainable, modular, and reproducible code. In 2020 and 2021 we focused on engineering and community building, and we announced our adoption by the Linux Foundation (AI & Data) in January 2022. In March 2023, we launched the Kedro blog; Kedro’s new branding was unveiled later that year, in June 2023. Then, in December 2024, Kedro achieved Graduation status within the LF AI & Data Foundation. What a journey!
As we reach Kedro 1.0, we want to be clear. It isn’t just a version number: it’s a statement of intent. A stable, curated core that gives you confidence to build, and a modular, extensible ecosystem that empowers you to grow. Whether you're designing your first pipeline or scaling complex workflows across teams, Kedro combines a foundation you can trust with the flexibility to adapt it for your individual project's needs.
At the heart of the release is a reimagined developer experience: a revamped DataCatalog, clearer namespace management, improvements to the runners, and a polished public API designed for longevity. Surrounding that core is a flourishing ecosystem, including the long-awaited “run only missing” feature, Kedro Viz’s new run status view, and a completely redesigned documentation experience that helps you onboard faster.
Kedro 1.0 provides a solid launchpad: a stable, reliable foundation that supports teams confidently exploring today’s universe of traditional machine learning and data science. But importantly, it also keeps sight of what’s coming next: the rapidly expanding frontier of generative AI and new data paradigms. A true multiverse! We’re preparing to explore it beyond 1.0.
The Core: Solid, Clear, and Built to Last
For this release, we focused on providing a stable core that is ready for more. Apart from dozens of bug fixes and small quality improvements, here is a list of highlights included in Kedro 1.0.
Revamped DataCatalog
We’ve been brewing a new DataCatalog for around a year, after a broad research workstream that surfaced several pain points from users, and we are very excited about the result.
Most importantly, datasets are now first class citizens and you can easily retrieve, add, and iterate over them:
1# Get a dataset
2reviews_ds = catalog["reviews"] # Direct dict-like access
3intermediate_ds = catalog.get(
4 "intermediate_ds",
5 version="2024-...", # Extra options by using .get()
6)
7
8# Add a dataset
9bikes_ds = CSVDataset(filepath="../data/01_raw/bikes.csv")
10catalog["bikes"] = bikes_ds # Direct assignment
11catalog["cars"] = ["Ferrari", "Audi"] # Raw data gets added as MemoryDataset
12
13for ds_name in catalog: # Iterate over dataset names
14 pass
15
16for ds in catalog.values(): # Iterate over dataset instances
17 pass
18
19for ds_name, ds in catalog.items(): # Iterate over (name, dataset) tuples
20 passThese improvements affect the Python API of the catalog, regular users of catalog.yml shouldn’t observe any changes. You can read more in our documentation.
User experience improvements to namespaces
Namespaces are great: they allow you to split your pipelines into non-overlapping portions, which is excellent for deployment use cases. However, they were not very well understood, and had some usability issues.
We have made significant user experience improvements to namespaces, including:
Possibility to use datasets in namespaces without having to prefix them, using the
prefix_datasets_with_namespaceof thePipelineinitializerChanged pipeline filtering for namespaces to return exact matches instead of partial ones
Support for running multiple namespaces within a single session
Added
Pipeline.group_nodes_by, which supports grouping by namespace
Improvements to runners
Runners are one of the key building blocks of Kedro. And yet, we’ve known some of them had usability issues that were preventing wider adoption.
Several improvements to the runners shipped as part of Kedro 1.0, including:
A new way to select which multiprocessing start method is going to be used on
ParallelRunnerCompatibility of
ParallelRunnerwithPartitionedDataset
As well as some internal refactorings that improve the maintainability of the code.
Polished public API
More broadly, we have made several improvements to the public API of Kedro. This included simplifying the default node names, making some widely used functions public (is_project, find_kedro_project), streamlining the pipelines codebase to avoid confusing IDEs, and much more.
The Ecosystem: Modular, Extensible, and Versatile
Reimagined new documentation
We are thrilled to present our fresh new documentation!
We completely redesigned the Kedro documentation to look more fresh, modern, and in line with the Kedro brand. In addition, we reshaped the documentation with a new information architecture that is easy to navigate, and introduced a table of contents on the right hand side that will make it easier for readers to browse pages. Finally, we modernised the installation instructions of Kedro to make it more clear how to use modern Python tools like uv, while still including guidance for other native Python tools (Poetry, pipx) as well as Conda.
Give the new docs a look! https://docs.kedro.org/en/1.0.0/
Long-awaited “Run only missing”
Kedro users have been asking for some functionality to do kedro run without re-executing nodes producing already available outputs for years. We finally came up with an implementation of the feature that fits with the Kedro architecture and shipped it!
Now you can run kedro run --only-missing-outputs and Kedro will skip nodes whose outputs already exist:
1$ kedro run --only-missing-outputs
2...
3 INFO Skipping 6 nodes with existing outputs: runner.py:213
4 compare_passenger_capacity_exp__822c8b63,
5 compare_passenger_capacity_go__1e477111,
6 create_confusion_matrix__2789b6a9, preprocess_companies_node,
7 preprocess_shuttles_node, train_model_node
8...More advanced change detection (like hashing to see if data or code is "stale") is something we plan to tackle soon. In the meantime, give it a try!
Workflow view
We are very excited to announce one of the biggest additions we have made in a while to Kedro Viz, which saw the light in version 12.0: a view that shows the run status of your pipeline!
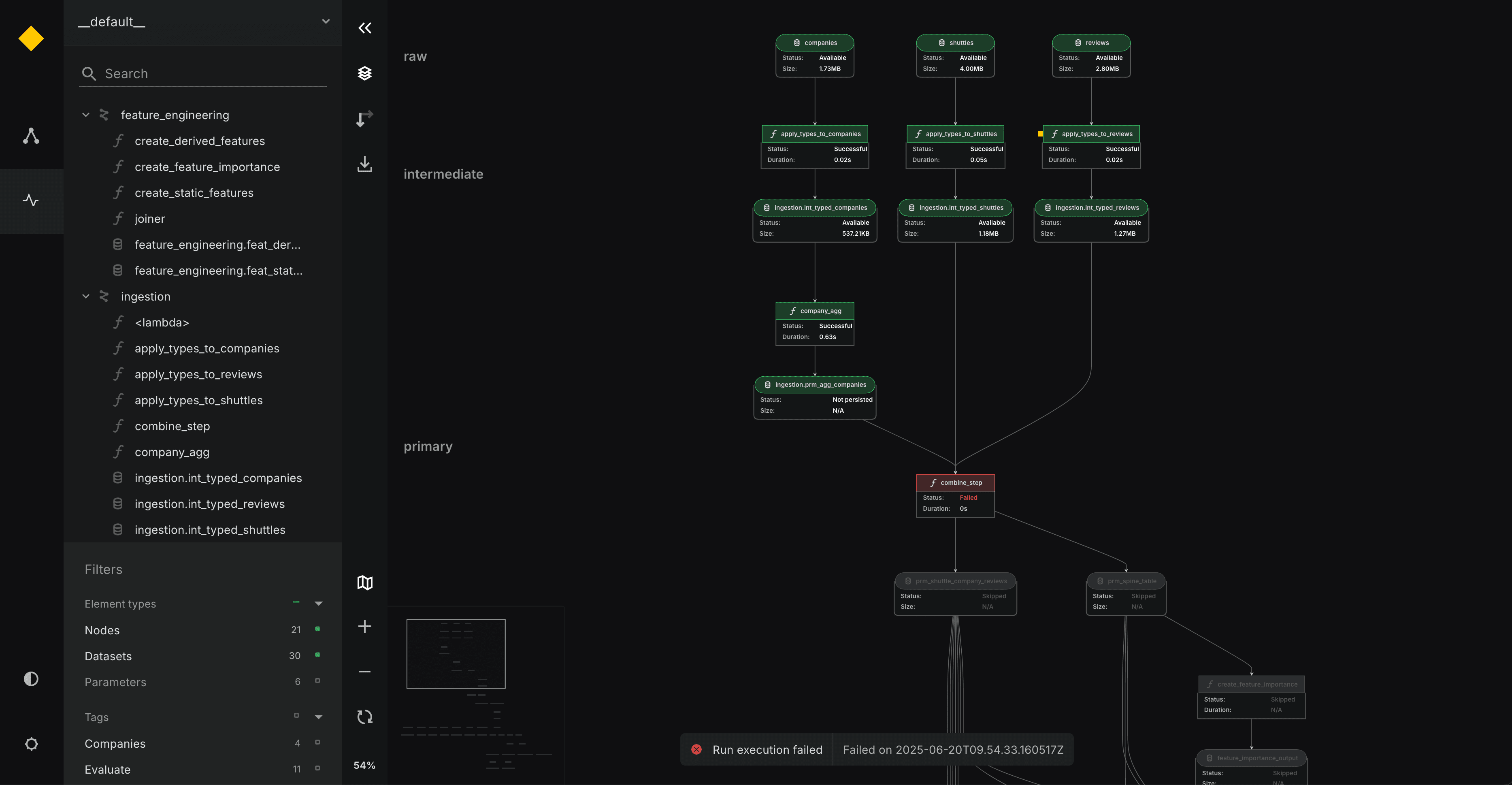
Another highly anticipated feature, this will allow users to quickly see at a glance whether their pipeline ran correctly, in a reasonable time, and whether the output datasets have the expected properties.
We plan to continue expanding this feature based on feedback from the community in the coming months. Give it a try and let us know what you think!
Community-driven integration with Databricks
As always, the Kedro ecosystem is buzzing with activity well beyond the activity of the core team. One such example is kedro-databricks, an extension created by Jens Peder Meldgaard that allows you to easily package your Kedro project as a Databricks Asset Bundle in 3 simple steps:
1$ kedro databricks init
2$ kedro databricks bundle
3$ kedro databricks deployJens already attended one of our regular Coffee Chats as a guest to present the plugin, and we’ve collaborated closely to bring a new documentation to life. We are always happy to collaborate with downstream plugin authors.
If you are using Kedro on Databricks, give this a try!
What’s next?
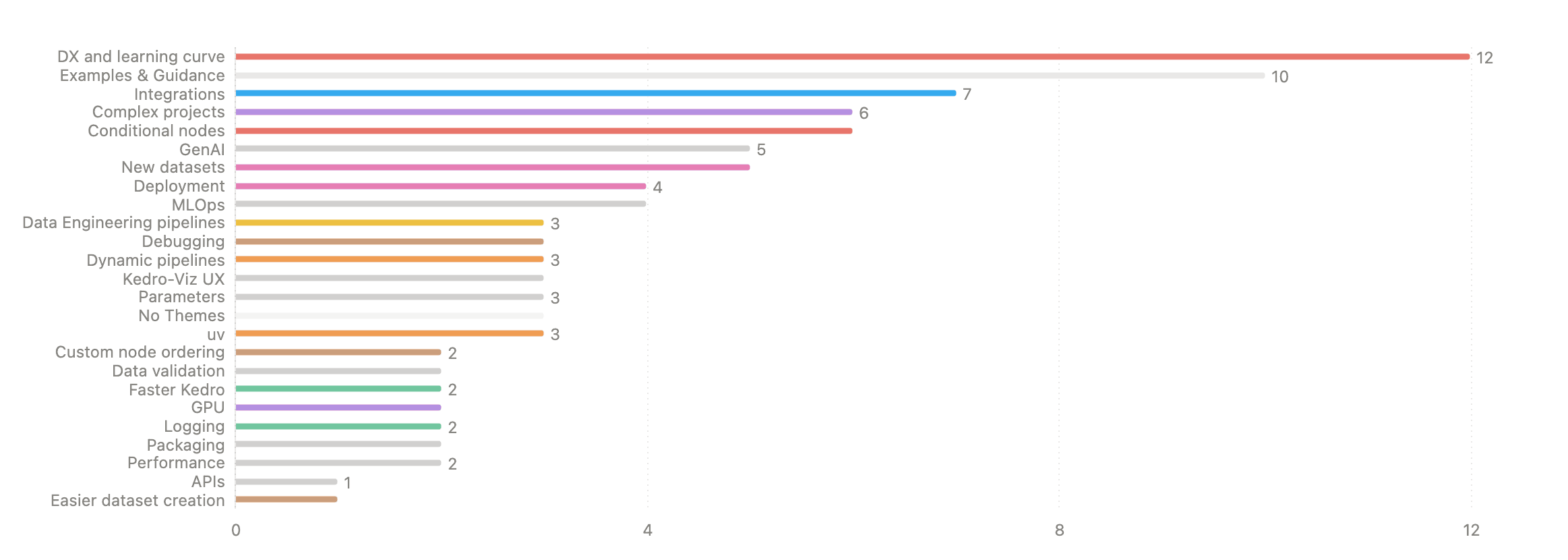
Of course we won’t stop here. Earlier this year we conducted a user survey to ask our community how they felt about Kedro and what ideas they had for the future. The response was excellent and more than 60 ideas were presented that we then categorized into different themes. The most popular ones were developer experience & learning curve, examples & guidance, integrations, complex projects, conditional nodes, and GenAI. But there were many more!
We are well aware that the work of Data Scientists is changing. On top of classical machine learning pipelines, the appearance of GenAI and agents has dramatically changed the data landscape.
Some challenges remain the same. Applying good software engineering principles to highly iterative and experimental code is still hard, and crafting production-ready agentic workflows is a new and developing challenge.
At the same time, LLM-powered code assistants are enabling users to produce technical debt at the fastest rate in history, while simultaneously struggling to refactor unstructured codebases.
We think that Kedro is ready to tackle these challenges head on. As such, our main priorities in 2025 and beyond will be making Kedro easier to learn and use, as well as opening up new possibilities for complex I/O patterns for the GenAI era.
The Humans Behind Kedro
This release would not have been possible without the hard work of the Kedro team at QuantumBlack Labs, as well as the rest of the Technical Steering Committee.

We are proud to celebrate the contributions of Huong Nguyen, Sajid Alam, Laura Couto, Nok Lam Chan, Juan Luis Cano, Ankita Katiyar, Elijah Ko, Rashida Kanchwala, Merel Theisen, Elena Khaustova, Dmitry Sorokin, Ravi Kumar Pilla, Jitendra Gundaniya, and Stephanie Kaiser, as well as TSC members Ivan Danov, Yetunde Dada, Deepyaman Datta, Joel Schwarzmann, Marcin Zabłocki, Simon Brugman, and Yolan Honoré-Rougé.
Get started with Kedro 1.0 today
And that’s a wrap. You can install Kedro with your favourite Python package managers, connect with the Kedro community in Slack to ask questions or stay up to date with news, and subscribe to our YouTube channel to receive notifications on new video content.
Find out more about Kedro
There are many ways to learn more about Kedro:
Join our Slack organisation to reach out to us directly if you’ve a question or want to stay up to date with news. There's an archive of past conversations on Slack too.
Read our documentation or take a look at the Kedro source code on GitHub.
Check out our video course on YouTube.





